4. Conoscere l’utente
Sintesi del capitolo
In questo capitolo si osserva che gli utenti possono essere
considerati da molteplici punti di vista. Possiamo studiare i processi
cognitivi che ne governano pensieri e azioni, le caratteristiche personali che
li caratterizzano nella loro individualità, i comportamenti, e, infine, il loro
ruolo nei confronti dei sistemi che utilizzano. Lo studio degli utenti da
questi diversi punti di vista richiede i metodi e le conoscenze di discipline
molto diverse, che possono fornire utili contributi alla disciplina della
human-computer interaction. Per il progettista di sistemi interattivi,
particolarmente utili sono le conoscenze della psicologia sperimentale e i
metodi dell’etnografia. Per quanto riguarda la prima, il capitolo introduce
brevemente alcune nozioni di base, utili al progettista, relative
all’attenzione, alla memoria, alla visione e al sistema motorio umano. Accenna
quindi ai metodi e alle funzioni nell’etnografia nel progetto di sistemi
interattivi.
La diversità degli utenti
Nel capitolo precedente si è visto come l’usabilità non sia
una proprietà intrinseca dei sistemi interattivi, ma una proprietà relativa
allo specifico utente, compito da svolgere e contesto di utilizzo. La grande
diversità degli esseri umani fa sì che, anche considerando compiti e contesti
d’uso simili, un oggetto potrebbe risultare usabile per un certo utente e del
tutto inusabile per un altro. Ecco perché la conoscenza dell’utente è di
importanza fondamentale per chi progetti sistemi. In questo capitolo vogliamo
approfondire questo tema.
La parola utente
deriva dal latino utens, participio
del verbo uti, che significa usare.
Quindi utente è, semplicemente, “colui che usa”, e in particolare, nel nostro
caso, colui che utilizza un prodotto o un servizio interattivo. Questo termine
spoglia, per così dire, l’utente della sua individualità. Definendo qualcuno
“utente”, scegliamo di ignorare tutto ciò che lo caratterizza come persona, e
di qualificarlo semplicemente in relazione al prodotto o al servizio di cui si
serve. Poiché non ne sottolineiamo le caratteristiche individuali, siamo
portati a considerarlo quasi una entità astratta. Questo è chiaramente
pericoloso, perché sposta la nostra attenzione sul sistema, di cui l’utente
diviene quasi un’appendice inessenziale. Come vedremo meglio nei prossimi
capitoli, l’approccio dell’ingegneria dell’usabilità, oggetto di questo libro,
è porre l’utente, e non il sistema, al centro dell’attenzione del progettista (Figura 1).
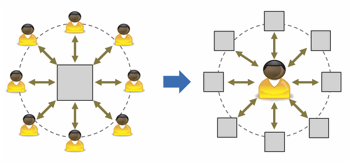
Figura 1. Da una visione centrata sul sistema a una visione centrata sull’utente
Lo studio dell’utente può essere compiuto a differenti
livelli. Al livello cognitivo,
consideriamo l’utente come essere umano dotato di specifiche abilità, derivanti
dalla struttura del suo corpo e della sua mente. Una creatura che percepisce,
interpreta, decide e agisce in un certo modo innanzitutto perché è dotato di un
apparato sensoriale, cognitivo e motorio con specifiche caratteristiche,
diverse da quelle di altre specie animali. Per fornirgli strumenti che possa
utilizzare con profitto, è necessario conoscere queste caratteristiche: non
possiamo chiedergli di svolgere compiti che non è fisicamente in grado di
eseguire, e non possiamo pretendere elaborazioni che il suo cervello non può
effettuare. A questo scopo, utilizziamo le conoscenze dell’ergonomia e
dell’ergonomia cognitiva, che a loro volta si basano sulle conoscenze
scientifiche derivanti dallo studio della psicologia e della fisiologia umana.
Le diversità fra esseri umani, anche considerando solo il
livello cognitivo, sono rilevanti. Quando poi, da quest’ambito strettamente
funzionale, passiamo a considerare gli utenti come persone, ciascuno con una specifica formazione, cultura e storia
personale, le diversità si fanno ancora più marcate, e caratterizzano ogni
specifico utente nella sua individualità. La persona Roberto non sarà solo descritta da parametri
che ne determinano le prestazioni fisiche e cognitive. Roberto avrà un’età, un
luogo di nascita, una lingua, una formazione, una professione, una storia
personale. Avrà motivazioni, preferenze, interessi, amicizie, relazioni e
sogni. Tutto ciò ne fa un individuo unico, diverso da ogni altra persona, e ne
influenzerà i comportamenti, in modo molto specifico.
Quando, oltre alle caratteristiche individuali, vogliamo
studiare il comportamento delle
persone, dobbiamo considerarne anche i rapporti che queste hanno con gli altri, e in
particolar modo con i membri delle comunità e organizzazioni cui appartengono.
La conoscenza dei comportamenti degli utenti, nelle loro relazioni a uno
specifico prodotto o servizio, ha un grande valore per il progettista. Solo
conoscendone in dettaglio i comportamenti egli sarà in grado di
comprenderne i problemi e le
necessità, e, quindi, di individuare le soluzioni più adeguate.
Un livello di analisi dell’utente ancora diverso è quello
che ne analizza il suo ruolo in
rapporto al sistema. In una rappresentazione teatrale, o in film, il ruolo è la
parte sostenuta da un attore: diciamo che un certo attore interpreta il ruolo
di protagonista, o di caratterista, o di comparsa o, ancora, del marito, o del
seduttore, e così via. Il ruolo è la funzione che questa persona svolge in
rapporto alla rappresentazione.[1] Analogamente, gli
utenti di un sistema interattivo possono rivestire ruoli diversi, secondo la
funzione che esercitano in rapporto ad esso. Per esempio, un utente di un sito
web con il ruolo di amministratore svolge
una funzione diversa da quella dei redattori
dello stesso sito. Infatti, essi hanno compiti, responsabilità e diritti di
accesso differenti. L’amministratore può cambiare la struttura complessiva del
sito, il redattore può soltanto creare o modificare gli articoli nelle sezioni
a lui riservate. Ancora diverso è il ruolo dell’utente finale, cioè colui che accede al sito dalla rete, per
conoscerne i contenuti.
Persona e ruolo sono concetti diversi. Roberto e Marco sono
persone differenti, ma entrambi potrebbero rivestire uno stesso ruolo, per
esempio quello di redattore. Al contrario, due ruoli diversi potrebbero essere
rivestiti da una stessa persona (Figura 2). La definizione del
ruolo permette di separare le caratteristiche individuali della persona dagli
aspetti legati allo scopo dell’interazione con il sistema.
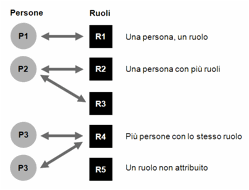
In conclusione, lo studio dell’utente può essere condotto su
piani diversi, in funzione degli aspetti che cui siamo interessati, come
suggerito nella Figura 3. Qui, lo schema a
piramide intende segnalare che le diversità fra gli utenti emergono ad ogni
livello: nelle prestazioni cognitive, nelle caratteristiche personali, nei
comportamenti, nei ruoli che gli utenti possono rivestire nell’interazione con
uno specifico sistema.
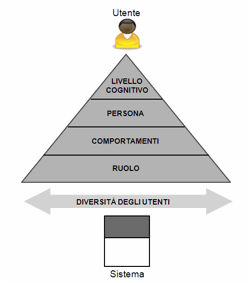
Figura 3. Livelli di descrizione dell’utente
Ogni livello deve essere studiato con metodi diversi. In
particolare, nella progettazione dei sistemi interattivi, sono particolarmente
utili, come vedremo nel seguito di questo capitolo, i metodi della psicologia sperimentale, che cerca di
determinare, con opportuni esperimenti, le prestazioni e i comportamenti
dell’essere umano in specifiche circostanze, e quelli dell’etnografia, che indaga i comportamenti delle persone, attraverso
metodi basati sull’osservazione diretta, nel contesto della loro vita
quotidiana.
Modelli dell’utente
Le caratteristiche del sistema
cognitivo dell’uomo sono studiate dalla psicologia, che fornisce molte
informazioni utili per chi si occupa di interazione uomo-macchina. Nell’ambito
di quest’ultima disciplina, sono stati proposti diversi modelli che rappresentano l’essere umano come
un sistema per elaborare le informazioni (human
information processor). Essi non pretendono di descrivere l’apparato
cognitivo umano come è nella realta, ma si limitano a metterne in evidenza le caratteristiche
più rilevanti per chi desideri studiare – o progettare –
l’interazione uomo-macchina. In particolare, questi modelli hanno permesso di
definire dei parametri quantitativi della “macchina umana” che permettono di
eseguire calcoli precisi sulle prestazioni teoricamente possibili per
l’esecuzione di particolari compiti, per esempio la digitazione di un testo su
una tastiera.
Una pietra miliare di questi studi è stata la pubblicazione,
nel 1983, del libro The Psychology of
Human-Computer Interaction, in cui gli autori Card, Moran e Newell rappresentavano l’utente con un modello
ispirato alla struttura di un computer (model
human processor, MHP, Figura 4). Da questo modello, e
utilizzando i risultati degli studi della psicologia sperimentale, riassumevano
una serie di parametri e di leggi di funzionamento della “macchina umana”, che
permettevano analisi quantitative dei compiti:
Il Model Human Processor può essere diviso in tre
sottosistemi interagenti: (1) il sistema percettivo, (2) il sistema motorio, e
(3) il sistema cognitivo, ciascuno con le sue memorie e processori. Il sistema
percettivo consiste di sensori e associati buffer di memoria. I buffer più
importanti sono quello per le immagini visive (Visual Image Store) e quello per
le immagini auditive (Auditory Image Store), che servono a contenere gli output del sistema sensoriale
mentre vengono codificati in modo simbolico. Il sistema cognitivo riceve
l’informazione codificata da questi buffer nella memoria di lavoro (working
memory) e usa l’informazione immagazzinata in precedenza nella memoria a lungo
termine (long-term memory) per prendere le decisioni su come rispondere. Il
sistema motorio porta a termine la risposta. In modo approssimato,
l’elaborazione dell’informazione da parte dell’essere umano sarà descritta come
se ci fossero dei processori separati per ciascun sottosistema: un processore
percettivo, uno cognitivo e uno motorio. Per alcuni compiti (premere un tasto
in risposta a una luce) l’essere umano si comporta come un processore seriale.
Per altri (digitare su una tastiera, leggere, fare una traduzione simultanea)
sono possibili operazioni parallele e integrate dei tre sottosistemi, come se
fossero tre processori in pipeline: l’informazione fluisce con continuità
dall’input all’output con un ritardo temporale caratteristico, che mostra che i
tre processori stanno lavorando simultaneamente. Le memorie e i processori sono
descritti da pochi parametri. [2]
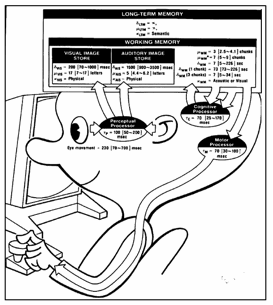
Figura 4.
Model Human Processor
(Card, Moran, Newell, 1983)
Il modello è complesso e, nelle quasi tre decadi trascorse
da allora, le conoscenze sulle caratteristiche dei processi umani sono
cresciute in modo considerevole. Non è quindi il caso di addentrarci, in questa
sede, in dettagli che possono essere studiati su testi specificamente dedicati
a questi argomenti. Ciò che qui interessa sottolineare è la grande portata
innovativa del metodo proposto da Card, Moran e Newell. In sostanza, la
conoscenza dei valori associati ai parametri che caratterizzano i processi
sensoriali, cognitivi e motorii dell’essere umano permette al progettista di
predire le prestazioni dell’utente tipico nell’effettuazione dei compiti
richiesti dal sistema in fase di progettazione. Questo può essere fatto sulla
carta, con calcoli più o meno complessi, senza la necessità di condurre
esperimenti di utilizzo del sistema da parte dell’utente (analisi dei compiti, o task
analysis). Il vantaggio di questo approccio è evidente. Il progettista
potrà valutare comparativamente soluzioni di progetto diverse, prima della loro
realizzazione, per scegliere quella più conveniente dal punto di vista
prastazionale.
In particolare, il metodo GOMS (Goals, Operators,
Methods, Selection rules), proposto nello stesso libro e in seguito
sviluppato in numerose varianti, decompone l’interazione con il sistema nelle
sue azioni elementari (che possono essere fisiche, come la pressione di un
tasto, percettive, o cognitive). I Goals
sono gli obiettivi che l’utente intende raggiungere, gli Operators le azioni da compiere per raggiungerli. I Methods sono le sequenze di operatori
disponibili per raggiungere ogni singolo goal. Quando ci sono più metodi
possibili, le Selection rules descrivono i criteri di selezione
di un metodo rispetto agli altri. Ad ogni azione elementare vengono associati
dei tempi di esecuzione, derivanti dal modello, e questi vengono poi sommati
tenendo conto dei metodi e delle regole di selezione.
Questa tecnica permette di individuare dei limiti
prestazionali, per esempio il tempo minimo necessario per copiare in una form
sul video i dati presenti su un documento cartaceo. Sono informazioni
importanti, ma hanno dei limiti. L’uomo non è una macchina, che – se
costruita con gli stessi componenti – si comporta sempre allo stesso
modo. Nell’essere umano le variazioni individuali sono rilevanti, e i parametri
utilizzati nel calcolo possono avere notevoli variazioni. Per esempio, l’età o
il possesso di particolari abilità o disabilità possono influenzare in modo
rilevante le nostre prestazioni. Inoltre, il nostro comportamento è influenzato
da numerosi fattori di cui il modello non tiene conto: la fatica, l’ambiente
circostante, i vincoli organizzativi, le motivazioni che abbiamo
nell’esecuzione del compito, e così via. Poi, durante l’interazione possiamo fare
degli errori, ed essere costretti a ripetere più volte alcune sequenze di
azioni. Oppure, ancora, possiamo non conoscere bene il sistema, e quindi usarlo
in modo diverso da quello teoricamente ottimale.
Dato lo scopo introduttivo di questo libro, non approfondiremo
più oltre i metodi di analisi dei compiti, come il GOMS. Descriveremo tuttavia, nel seguito di questo
capitolo, alcune caratteristiche del funzionamento dello “human processor”, che
sono di grande importanza per la progettazione e per lo studio dei sistemi
interattivi. Questi aspetti faranno riferimento allo schema di Figura 5, tratto dal MHP, con
qualche semplificazione e aggiunta. [3] Esaminiamo dunque singolarmente alcuni di questi componenti,
mettendone in evidenza le caratteristiche di nostro interesse. Data la natura
introduttiva di questo libro, e l’ampiezza delle problematiche coinvolte, ci
limiteremo a pochi cenni essenziali, rimandando il lettore che desideri
maggiori informazioni ai testi di psicologia generale.
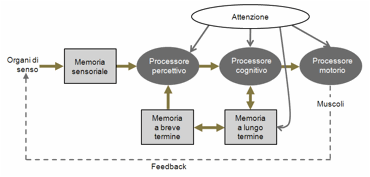
Figura 5. Model Human Processor adattato
L’attenzione
Tutti noi crediamo di sapere che cosa è l’attenzione, ma
definirla scientificamente è molto difficile, e le opinioni dei ricercatori
sono discordi. Infatti, questo termine non si riferisce a un fenomeno unitario,
ma piuttosto a una serie di processi psicologici fra loro molto differenti. Per
gli scopi di questo libro, la possiamo intendere, semplicemente, come
quell’insieme di processi cognitivi che ci permettono di selezionare, fra tutte
le informazioni che arrivano ai nostri sensi, quelle che in qualche modo ci
interessano. Selezionare significa ignorare determinati stimoli, a favore di
altri: per questo, viene spesso usata la metafora del filtro. Se non
possedessimo un meccanismo di filtraggio, l’informazione da elaborare in ogni
istante della nostra vita sarebbe eccessiva, perché il nostro apparato
cognitivo ha capacità limitate. Basti pensare alla quantità d’informazione
visiva che si presenta in ogni momento ai nostri occhi quando ci guardiamo
intorno, per comprendere che, se non ci fossero dei meccanismi di selezione,
saremmo costretti a elaborare un’enorme massa di dati che non ci servono. [4] Per esempio, quando
parliamo con una persona, di solito concentriamo la nostra attenzione sulle sue
parole, la sua bocca e i suoi occhi, e ignoriamo gli altri stimoli che
provengono dall’ambiente circostante. Se siamo in una strada rumorosa, fra
tutti gli stimoli che arrivano alle nostre orecchie selezioniamo solo le parole
del nostro amico, ignorando i clacson delle automobili e il rumore del
traffico, anche se fossero molto forti. Li percepiamo, ma restano in
sottofondo: descriviamo questa situazione dicendo, appunto, che non vi
prestiamo attenzione. Se però, mentre stiamo chiacchierando, qualcuno pronuncia
il nostro nome, noi ce ne accorgiamo. Non occorre che urli: anche se lo fa a
bassa voce, la nostra attenzione – che ignorava gli stimoli più forti dei
rumori stradali – viene attratta da questo nuovo stimolo, e ci consente
di elaborarlo. È come se scattasse un allarme, che ci distoglie per un momento
da ciò cui stavamo prestando attenzione, e ci costringe a rivolgerla altrove.
In altre situazioni, la nostra attenzione riesce a focalizzarsi (sia pure in
modo limitato) su più eventi in contemporanea, per esempio quando guidiamo
l’automobile mentre parliamo al cellulare.
Si parla di attenzione selettiva (selective
attention) quando ci focalizziamo su un singolo evento escludendo gli
altri, e di attenzione divisa (split attention) quando seguiamo contemporaneamente più eventi. Non
si tratta di due fenomeni indipendenti, ma di due aspetti dello stesso
fenomeno. Le teorie sull’attenzione che sono state elaborate, e i
numerosi studi sperimentali che cercano di confermarle, sono al di fuori degli
scopi di questo libro. Esaminiamo, invece, alcuni aspetti importanti per i temi
di nostro interesse.
Innanzitutto,
l’attenzione può essere influenzata da fattori esterni (esogeni) e interni (endogeni).
Nel primo caso, sono le caratteristiche degli stimoli che arrivano ai nostri sensi
che la influenzano, e numerosi studi cercano di determinare queste
caratteristiche. Come quando qualcuno ci chiama per nome. Oppure come quando la
nostra attenzione è attratta dal cerchio nero di Figura 6a, che spicca per la sua diversità fra
tutti gli altri cerchi bianchi.
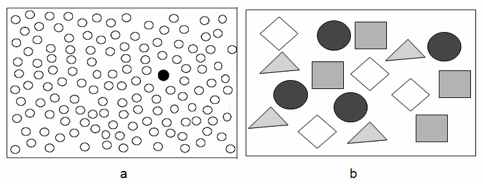
Figura 6. Test per attenzione selettiva
Nel
secondo caso, la nostra attenzione è guidata da noi stessi: dai nostri
obiettivi, dalle nostre emozioni, dai nostri pensieri. L’importanza dei fattori
endogeni è resa evidente da molti semplici esperimenti, come il seguente. Si
mostri a qualcuno la Figura 6b, e gli si chieda di contare i triangoli.
Poi si nasconda la figura e gli si chieda il numero dei quadrati bianchi. Il
nostro interlocutore non sarà in grado di rispondere: il compito che si era
assegnato (contare i triangoli) gli aveva fatto ignorare tutte le altre
informazioni. La sua attenzione era rivolta esclusivamente ai triangoli.
La
nostra attenzione è tanto più focalizzata quanto più siamo impegnati in un
compito difficile. Se si mostra a un soggetto un breve video di una squadra di
pallacanestro in azione, chiedendogli di contare quante volte i giocatori si
passano la palla, egli sarà così concentrato su questo compito, piuttosto
impegnativo se i passaggi sono rapidi, da non vedere altri eventi che si
svolgono nel campo da gioco. Per esempio, non si accorgerà che un attore
vestito da gorilla passeggia tranquillamente fra i giocatori.[5]
Consideriamo
ora l’attenzione divisa. Essa ha possibilità limitate: non siamo in grado di
prestare attenzione a troppe cose contemporaneamente. Durante la visione del
video di cui sopra, quasi certamente non riusciremo a contare,
contemporaneamente, i passaggi di palla, i giocatori con i baffi e quelli con i
capelli biondi. Gli esperimenti
mostrano che quando cerchiamo di prestare attenzione a più compiti
contemporaneamente, le prestazioni sono in genere peggiori di quelle ottenute
quando siamo impegnati negli stessi compiti, ma uno per volta. I sistemi che
richiedono all’utente attenzione divisa possono risultare quindi poco usabili.
Interfacce con queste caratteristiche sono per esempio quelle che servono a controllare apparati
complessi, come il cruscotto di un aereo (Figura 7). Il progettista dovrà tenerne conto, e
semplificare l’interfaccia in modo opportuno.

Figura 7. Il cruscotto dell’U2, un aereo da ricognizione monoposto della Lockheed prodotto dagli anni ’50
I
sistemi operativi oggi permettono di eseguire più programmi contemporaneamente
(multitasking): per un computer, la
capacità di ”attenzione divisa” è limitata solo dalla potenza del processore.
Per gli esseri umani, queste capacità sono, come abbiamo visto, piuttosto
limitate. Sembra, tuttavia, che l’abitudine a seguire al computer più processi
che avvengono in contemporanea costituisca una sorta di addestramento, che
migliora le nostre capacità di attenzione divisa. In effetti, i giovani
abituati a usare il computer fin dai primi anni di vita (nativi digitali) eseguono spesso molti compiti in parallelo:
rispondono alle mail, chattano con gli amici, inviano e ricevono messaggi su
una social network, ascoltano musica, navigano in internet. Questo porta a una
grande frammentazione delle attività, che persone di generazioni precedenti non
riescono a gestire con la stessa facilità.[6]
In ogni
caso, è evidente che il Web pone oggi agli utenti formidabili problemi di
esercizio dei propri meccanismi attentivi. Come osserva Howard Rheingold:
L’attenzione
è l’alfabetizzazione fondamentale. Ogni secondo che passo online, io prendo
decisioni su dove dirigere l’attenzione. Devo dedicare la mia mente a questo
commento o a questo titolo? – una domanda alla quale devo rispondere ogni
volta che un link interessante attira il mio sguardo. Semplicemente diventando
consapevole che la vita online richiede questo tipo di decisioni, questo è
stato il mio primo passo nell’apprendere a regolare un filtro fondamentale a
ciò che permetto di entrarmi in testa – un filtro che è sotto il mio
controllo soltanto se mi esercito a controllarlo. Il secondo livello di
decisione è se desidero aprire un tab nel mio browser perchè ho deciso che
questo elemento meriterà un po’ del mio tempo domani. La terza decisione: creo
un bookmark a questo sito perché mi interessa e potrei desiderare di
utilizzarlo in un imprecisato futuro? Domare la propria attenzione online
inizia con ciò che i meditatori chiamano “mindfulness” – la semplice,
controllata consapevolezza di come la nostra attenzione vaga qua e là.[7]
In sintesi,
le richieste che un sistema pone ai meccanismi attentivi dell’utente possono
influenzarne in modo molto rilevante l’usabilità. Durante la progettazione di un sistema interattivo si
dovranno, quindi, considerare approfonditamente i seguenti aspetti:
· come mantenere costantemente l’attenzione dell’utente sugli elementi desiderati dell’interfaccia;
· come evitare interferenze indesiderate, che sottraggano l’attenzione dell’utente da tali elementi;
· come ridurre al minimo le richieste di attenzione divisa poste dall’interfaccia.
Il primo obiettivo si può conseguire
realizzando degli opportuni indizi
attentivi (attentional cue) che
attraggano e guidino l’attenzione dell’utente dove si desidera. L’esempio forse
più semplice è il puntatore del mouse, che non serve solo a selezionare
l’oggetto desiderato, ma anche a portare l’attenzione dell’utente sulla zona
dello schermo più rilevante per il compito che sta eseguendo.
Quando il campo visivo è troppo
ampio o troppo complesso, si dovranno studiare degli indizi attentivi
particolari. Per esempio, la Figura
8 mostra una sofisticata soluzione basata sulla
metafora del proiettore teatrale (spotlight),
per guidare l’attenzione degli spettatori in una sala per presentazioni dotata
di 6 grandi schermi. L’area d’interesse dello schermo viene illuminata da un
ampio spot circolare, che segue il cursore controllato dal presentatore.
Contemporaneamente, le aree rimanenti in tutti gli schermi vengono leggermente
oscurate. Quando il cursore si muove, l’area intorno allo spot è meno scura del
resto, per permettere a chi guarda di seguirlo con facilità.[8]

Figura 8. Guida all’attenzione in una sala multi-schermo
Non è necessario che gli indizi
attentivi siano di grandi dimensioni. La Figura 9 mostra la homepage del sito di uno studio grafico, di un colore rosso
vivo, con scritte bianche. Un minuscolo bottone nero con una freccia permette
di entrare nel sito. Non importa che sia molto piccolo: la diversità di colore
è così marcata, che l’attenzione dell’utente è immediatamente attratta su
questo punto, come nel caso del pallino nero di Figura 6.
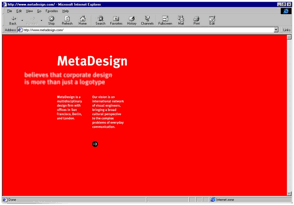
Figura 9. http://www.metadesign.com (circa 1996-2000)
La Figura
10 mostra la tecnica utilizzata nell’iPhone per
segnalare la presenza di telefonate, sms e mail non ancora letti: un piccolo
cerchio (di colore rosso vivo, e quindi ben visibile) appare sulle icone che
permettono di gestire, rispettivamente, telefonate, sms e mail. Il numero nel
cerchio segnala quanti sono gli elementi nuovi.

Figura 10. Indizi attentivi nell’iPhone (Apple, 2007)
La memoria
La memoria umana può essere rappresentata con il semplice
modello di Figura
11, spesso chiamato modello
modale.[9]
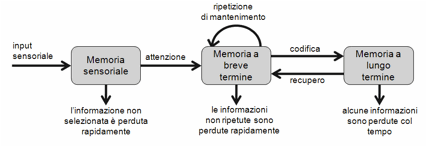
Figura 11. Modello modale della memoria umana
Questo modello, chiaramente ispirato all’information
processing, ipotizza l’esistenza di una serie di fasi, attraverso cui l’informazione
transita, e una serie di “magazzini” destinati a contenerla. In particolare, i
dati sensoriali non ancora elaborati sono inizialmente acquisiti in memorie sensoriali (sorta di buffer o
registri temporanei associati agli organi di senso, dove i dati grezzi
permangono per un tempo molto breve – frazioni di secondo). Vengono
quindi selezionati attraverso meccanismi in cui gioca un ruolo importante
l’attenzione, e caricati in una memoria a
breve termine (short-term memory, o STM), che è ritenuta il componente
principale dove avvengono le elaborazioni mentali. La permanenza nella STM è
molto breve: essi sono utilizzati per supportare i processi cognitivi in atto,
e subito eliminati oppure trasferiti, con un atto consapevole, nella memoria a lungo termine (long-term memory, LTM) per una
ritenzione permanente. In pratica, secondo questo modello, la memoria a breve
termine viene utilizzata per contenere i dati in corso di elaborazione; per
questo, viene anche chiamata memoria di
lavoro (working memory). La memoria
a lungo termine, invece, è il deposito permanente – o comunque di
lunghissima durata – di tutto quanto conosciamo.
Questo modello corrisponde bene alla nostra conoscenza
intuitiva del funzionamento della memoria umana. Quando dobbiamo telefonare a
un amico, cerchiamo prima il numero di telefono nell’agenda. L’informazione
visiva transita nella memoria sensoriale del sistema visivo, e poi, trasformata
in qualche modo in numeri, viene depositata nella memoria a breve termine. Da
qui la preleviamo quando componiamo il numero. Subito dopo, essa viene di
solito dimenticata, perchè non ci serve più.
Se dopo avere memorizzato il numero veniamo interrotti da
qualcuno che ci chiede un’informazione, usiamo la memoria a breve termine per
questo nuovo compito, e scordiamo il numero (interferenza). In ogni caso, non possiamo ricordare il numero a
lungo: lo dobbiamo usare quasi subito, altrimenti lo scordiamo. Se lo vogliamo
ricordare più a lungo, dobbiamo trasferirlo nella memoria a lungo termine. Per
questo, dobbiamo ripeterlo mentalmente molte volte (reiterazione, o rehearsal),
o utilizzare altre tecniche che facilitino la memorizzazione.
Gli psicologi hanno effettuato numerosi esperimenti per
verificare la correttezza del modello seriale di Figura 11, e per individuare le prestazioni dei diversi sistemi
di memoria. Descriveremo solo quelle che sono particolarmente utili a chi si
occupa di interazione uomo-macchina.
La memoria a breve termine
Per quanto riguarda la memoria a breve termine, una pietra
miliare è il classico articolo The magical number seven, plus or minus two,
pubblicato da G.A.Miller nel 1956.[10] In questo lavoro,
Miller quantifica la capacità della
STM in 7±2 elementi di informazione, detti chunk
(il “magico” numero 7 del titolo). Un chunk (letteralmente, “pezzo”), è un raggruppamento
di elementi che trattiamo in modo unitario. In sostanza, il massimo numero di raggruppamenti
che la memoria a breve termine dell’uomo può contenere è compreso fra 5 e 9, a
seconda dei casi.
Definire con precisione che cosa sia un chunk non è facile,
ma lo si può capire facendo degli esperimenti. Riferendoci alla Figura
12, consideriamo la sequenza 1, composta da 6 lettere.
Essa può essere facilmente ricordata nella memoria a breve termine: possiamo
considerare ogni lettera un chunk. La sequenza 2, composta da 9 lettere/chunk,
è al limite: la ricordiamo, ma probabilmente con qualche difficoltà. Invece, è
molto probabile che non riusciremo a ricordare la sequenza 3, composta da 15 lettere/chunk, perché
troppo lunga. Se però consideriamo la sequenza 4, anch’essa composta da 15
lettere, non avremo difficoltà a
ricordarla. Le lettere, infatti, non sono fra loro scorrelate, ma costituiscono
una coppia di elementi che percepiamo come unitari: il nome WILLIAM e il
cognome MCMILLAN. Nello stesso modo, la sequenza 5 non ci crea troppe
difficoltà: in questo caso, ogni parola costituisce un singolo chunk, anche se è composta da più lettere.
Poiché le parole sono sette, la sequenza non eccede la capacità della STM.
Invece, la sequenza 6 (11 chunk/parole scorrelate) è troppo lunga.
La memoria a breve termine può
rivelarsi considerevolmente capace, se effettuiamo un opportuno chunking (se, cioè, creiamo degli
opportuni raggruppamenti dotati di significato). La sequenza 7 in Figura 12, composta di ben 75 lettere e 15 parole, non è difficile da ricordare. Possiamo
spezzarla infatti in pochi chunk.
Quanti? Dipende da come la scomponiamo. Per esempio, in tre parti: LA PICCOLA
VOLPE ROSSA - SALTò SUL GROSSO
CANE RANDAGIO - E LO FECE RUZZOLARE SUL MARCIAPIEDE.

Figura 12. Test per il “magico numero sette”
Si può notare che anche per ricordare i numeri di telefono
usiamo la tecnica del chunking. Fino alle classiche sette cifre, non abbiamo
troppi problemi. Se però dobbiamo ricordare anche i prefissi, le cifre
diventano una dozzina, e allora scomponiamo il numero in chunk di più cifre,
per esempio così: +39-335-XXXX-YYY.
Per quanto riguarda la permanenza
dell’informazione nella STM, altri esperimenti dimostrano che è molto breve (meno
di 20 secondi), a meno che l’informazione non venga “ripetuta mentalmente” (reiterazione, o rehearsal), con un processo che richiede attenzione. Così facendo,
siamo in grado di ritenere un’informazione anche molto a lungo. La durata può
ridursi ulteriormente, se facciamo del lavoro cognitivo impegnativo che, in
qualche modo, “sovrascrive” i contenuti precedenti (interferenza).
Un esperimento classico per dimostrare la limitata durata
della memoria a breve termine fu condotto da Peterson e Peterson, nel 1959.[11] A un insieme di
soggetti veniva presentato un gruppo di tre consonanti (per esempio FDZ),
immediatamente seguito da un numero di tre cifre (per esempio 100). Il soggetto
doveva iniziare subito a contare all’indietro, per tre, dal numero indicato
(100, 97, 94, …). Quando veniva
interrotto dallo sperimentatore, doveva rievocare le tre consonanti. Il conteggio
all’indietro serviva a impedire che “ripetesse mentalmente” le lettere da
ricordare. La Figura
13 mostra la percentuale di rievocazioni corrette, in
funzione del tempo trascorso dalla presentazione. Si vede che la capacità di
rievocazione degrada molto in fretta: dopo una diecina di secondi, è circa del
30%, dopo una ventina di secondi, del 10%. In altre parole, dopo venti secondi,
nel 90% dei casi il contenuto della memoria a breve termine è già perso.
Nella stessa figura, la linea tratteggiata mostra che cosa
succedeva quando ai soggetti venivano presentate tre parole, invece di tre
consonanti. Le prestazioni erano identiche, a dimostrazione di quanto detto a
proposito del chunking: una parola viene trattata come un singolo chunk,
proprio come una lettera.
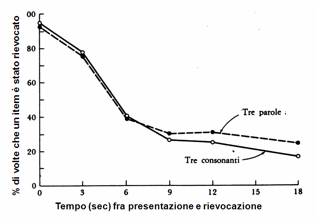
Figura 13. L’esperimento di Peterson e Peterson (1959)
Non sempre i progettisti tengono nella dovuta considerazione
le limitazioni della memoria a breve termine: non sono pochi i sistemi che
richiedono agli utenti prestazioni che non sono in grado di svolgere. La Figura
14, tratta da PowerPoint 2003, mostra un esempio tipico.
Durante la preparazione di una presentazione, se si chiede al sistema di help come
si cambia il layout di una slide, si ottene sul video una finestra con le
istruzioni richieste. Fin qui, tutto bene. Ma, quando iniziamo a eseguire
queste istruzioni, la finestra con la slide si porta in primo piano, coprendo
quella con le istruzioni. Per eseguirle, dobbiamo ricordarle, poichè non le
possiamo vedere. Questo risulta difficile quando le istruzioni superano i
limiti espressi dal “magico numero sette”. Come se non bastasse, mentre
eseguiamo le istruzioni dobbiamo compiere altre attività cognitive: muovere il
mouse, aprire i menu indicati, selezionare le voci corrette, verificare i
risultati di queste operazioni, e così via. Tutto ciò ci impedisce di ripetere
mentalmente le istruzioni da compiere, per ricordarle. In sostanza, le
dimentichiamo prima di averle portate a termine.
Per superare queste difficoltà, dovremmo cliccare
alternativamente sulle due finestre,
quella con la slide che stiamo preparando e quella con le istruzioni,
per rileggerle quando ci servono. Oppure, semplicemente, dovremmo prendere nota
delle istruzioni su un foglio di carta. Ma allora a che serve il computer? La
soluzione progettuale corretta è ovvia (e infatti è stata adottata nelle
successive versioni di PowerPoint): fare in modo che la finestra con le
istruzioni rimanga sempre in primo piano, anche mentre si opera sull’altra.
Ovviamente, l’utente dovrà poterla spostare dove vuole, per evitare che
intralci le operazioni.
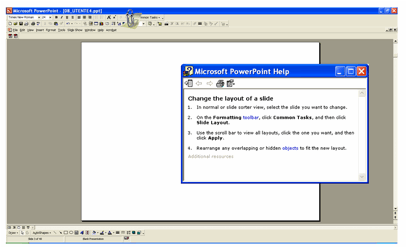
Figura 14. Help in Microsoft PowerPoint 2003
Nei prossimi capitoli vedremo altri esempi di sovraccarico (overloading) della memoria a breve
termine dell’utente. Sono tutte situazioni tipiche, che si incontrano spesso
nei sistemi interattivi, e che dovrebbero essere sempre evitate. La Figura 6 nel Capitolo 10 mostra un
esempio simile a quello appena descritto, relativo a un messaggio di help. La
Figura 12 nel Capitolo 11 mostra un lungo elenco di segnalazioni di errori
commessi dall’utente, che questi deve memorizzare prima di poterli correggere.
La Figura 8, sempre nel Capitolo 11, segnala un altro caso molto frequente: le
istruzioni vocali di un call center telefonico, con un numero eccessivo di
opzioni. L’utente le deve memorizzare tutte, prima di poter decidere quella che
meglio si adatta ai suoi scopi. Anche in questo caso, viene coinvolta la
memoria a breve termine.
In sintesi, il progettista di sistemi interattivi dovrà
sempre evitare di sovraccaricare la memoria a breve termine dell'utente:
· facilitandogli il chunking, cioè richiedendogli di memorizzare solo elementi che abbiano un significato o che siano familiari, e in numero limitato (7±2);[12]
· minimizzando comunque le richieste di memorizzazione in presenza di altre attività cognitive, per evitare interferenze.
La memora a lungo termine
La
memoria a lungo termine è un sistema molto complesso. Essa ci consente di
ricordare le informazioni per molto tempo: potenzialmente, per tutta la vita.
Alcuni autori la considerano costituita da due grandi sottosistemi, che
svolgono compiti diversi: la memoria
dichiarativa, e quella procedurale.
La prima riguarda tutte le conoscenze esprimibili a parole che si hanno sul
mondo; la
seconda conserva le conoscenze su come
fare le cose: andare in bicicletta,
annodare il nodo della cravatta, giocare a tennis, digitare alla tastiera di un
computer. Queste conoscenze non sono verbalizzabili: ci facciamo agevolmente il
nodo della cravatta, ma non siamo in grado di descrivere con precisione quali
movimenti compiamo. È come se la memoria procedurale ricordasse i movimenti del
nostro corpo, ma non le loro descrizioni.
La
memoria dichiarativa, a sua volta, può essere decomposta in due sottosistemi:
la memoria episodica e quella semantica. La prima, come suggerisce il
nome, registra i fatti che avvengono nel tempo: la caduta del muro di Berlino,
i risultati delle ultime elezioni. Se gli episodi riguardano la vita della
persona che li ricorda (per esempio dove ha passato le ultime vacanze), si
parla di memoria autobiografica. Nella memoria semantica, invece,
conserviamo le conoscenze generali sul mondo: il prezzo di un oggetto, il nome
del Presidente della Repubblica, tutto ciò che abbiamo imparato a scuola.
Un
sistema interattivo sollecita tutte le funzioni della memoria dei suoi utenti.
Innanzitutto, la memoria semantica, per quanto riguarda ciò che l’utente
conosce, dal punto di vista teorico, sull’uso del sistema: il significato delle
voci dei menu o dei tasti di scelta rapida, l’esistenza o meno di determinate
funzioni. Quindi la memoria procedurale, per le modalità di interazione: per
esempio, l’uso della tastiera e del mouse, la selezione della voce di un menu.
Infine, la memoria episodica, per quanto riguarda la storia dell’interazione
con il sistema. Per esempio, quando utilizziamo un word processor, ricordiamo
di avere salvato il file pochi minuti fa, oppure che ieri ne abbiamo cambiato i
valori di default.
Gli
psicologi studiano i processi di codifica
(encoding) e di recupero (retrieval)
dell’informazione nella/dalla memoria a lungo termine (Figura 11). Per codifica intendiamo i processi che
attuiamo per memorizzare qualcosa: quando studiamo un libro, quando “impariamo
a memoria” una poesia, oppure quando memorizziamo la password di accesso al
nostro computer. Il recupero si riferisce, invece, ai processi che attiviamo
per rievocare qualcosa che abbiamo memorizzato. Vediamo brevemente gli aspetti che
ci interessano.
Codifica
Le
informazioni che ci sono state presentate ripetutamente sono più facile da
ricordare. Pertanto, la tecnica più elementare per memorizzare un’informazione
nella memoria a lungo termine consiste nel “ripeterla mentalmente” una o più
volte, prestando attenzione al suo significato, come facciamo quando ripassiamo
una lezione (reiterazione, o rehearsal). Non bisogna confondere la
semplice ripetizione con la reiterazione. La ripetizione si riferisce al fatto
che un elemento viene incontrato più di una volta. Reiterazione, invece, significa
che esso viene “pensato ripetutamente”, in un processo volontario che richiede
attenzione. Per esempio, quando sul giornale incontriamo più volte il nome di
un ministro, è ripetizione. Quando lo ripetiamo mentalmente per ricordarcelo, è
reiterazione.
Sappiamo
che il recupero di un’informazione dalla memoria è facilitato dalla presenza di
associazioni fra l’informazione
cercata e altre già note. Per
esempio, per ricordare il nome di Bill Gates potremmo associarlo all’immagine
del cancello del nostro giardino, perché Gates in inglese significa “cancelli”.
Possiamo anche inventare degli ausilii
mnemonici (memory aids) più
sofisticati, che utilizzano associazioni di vario tipo. Per esempio, per ricordare la
suddivisione delle Alpi, si utilizza spesso la frase:
Ma con gran pena le reca giù
composta
dalle sillabe iniziali dei nomi da ricordare:
MArittime, COzie, GRAie, PENnine, LEpontine, REtiche, CArniche, GIUlie.
Il progettista di sistemi
interattivi può suggerire in molti modi queste associazioni all’utente,
affinchè ricordi meglio i comandi del sistema. Per esempio, in Microsoft Office
2003, i tasti di scelta rapida sono definiti utilizzando le iniziali dei
comandi cui si riferiscono: Print ↔ CTRL P; Save ↔ CTRL S;
Open ↔ CTRL O (Figura
15).[13]
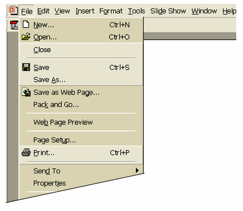
Figura 15. Ausilii mnemonici in Microsoft Office 2003
I metodi per memorizzare le informazioni si chiamano mnemotecniche. Gli esempi che abbiamo
visto sono molto semplici, ma ne sono stati elaborati di assai più sofisticati,
che però richiedono uno specifico
addestramento. Nell’antichità, gli oratori utilizzavano mnemotecniche raffinate
per ricordare i discorsi da pronunciare senza l’ausilio di un testo scritto,
(la carta è invenzione relativamente recente). Esse sfruttavano il fatto che
ricordiamo meglio le informazioni associate a immagini visive o a storie. Per
esempio, Ad Herennium, un testo
anonimo dell’85 a.C. circa, consiglia di associare alle informazioni da
ricordare immagini di natura eccezionale (imagines
agentes):
Quando, nella vita di ogni giorno, vediamo cose meschine,
usuali, banali, generalmente non riusciamo a ricordarle, perché la mente non ne
riceve nessuno stimolo nuovo o inconsueto. Ma se vediamo o udiamo qualcosa di
eccezionalmente basso, vergognoso, inconsueto, grande, incredibile o ridicolo,
siamo soliti ricordarcene a lungo. […] Dobbiamo, dunque, fissare immagini di
qualità tale che aderiscano il più a lungo possibile nella memoria. E lo faremo
fissando somiglianze quanto più possibile straordinarie; se fissiamo immagini
che siano non molte o vaghe, ma efficaci (imagines agentes); se assegnamo ad
esse eccezionale bellezza o bruttezza singolare; se adorniamo alcune di esse ad
esempio con corone o manti di porpora per rendere più evidente la somiglianza,
o se le sfiguriamo in qualche modo, ad esempio introducendone una macchiata di
sangue o imbrattata di fango o sporca di tinta rossa, così che il suo aspetto
sia più impressionante; oppure attribuendo alle immagini qualcosa di ridicolo,
poiché anche questo ci permette di ricordarle più facilmente.
Un metodo molto diffuso nell’antichità per memorizzare un
discorso consisteva nell’associarne i diversi passaggi alle stanze di un
palazzo, e agli oggetti che contenevano (meglio se rappresentati da imagines
agentes, nel senso descritto sopra). L’oratore, quindi, poteva percorrere con
la mente le stanze in un ordine prefissato, ritrovando gli oggetti contenuti e
recuperando così, via via, i passaggi del discorso ad essi associati. Come
spiega Cicerone nel De Oratore, il
suo trattato sull’arte oratoria:
Le persone desiderose di addestrare la memoria devono
scegliere alcuni luoghi e formarsi immagini mentali delle cose che desiderano
ricordare, e collocare quelle immagini in quei luoghi, in modo che l’ordine dei
luoghi garantisca l’ordine delle cose, le immagini delle cose denotino le cose
stesse, e noi possiamo utilizzare i luoghi e le immagini rispettivamente come
la tavoletta cerata e le lettere scritte su di essa.
Questa “tecnica dei luoghi” fu usata fino al Rinascimento in
numerose varianti. La Figura
16 riporta un’illustrazione di un testo cinquecentesco
di mnemotecnica. In questo caso, si utilizza un’abbazia con gli edifici
annessi, raffigurati nell’immagine a sinistra. A destra sono rappresentati gli
oggetti da collocare nei diversi luoghi dell’abbazia (il cortile, la
biblioteca, la cappella), che fungeranno da ancore mnemoniche per i diversi
passaggi del discorso da ricordare. Ogni quinto posto è contrassegnato da una
mano, e ogni decimo da una croce, con un’ovvia associazione alle dita delle due
mani, con le quali ci si aiutava nell’enumerazione.[14]

Figura 16. Johannes Romberch, Congestorium artificiose memorie (Venezia, 1533)
Oggi i discorsi sono fatti con
l’ausilio del computer, e non abbiamo più bisogno di imparare queste tecniche
complesse. Tuttavia, possiamo ancora seguire i consigli degli antichi, e
utilizzare le imagines agentes. Per
esempio, il nome del WWF è strettamente associato all’immagine del panda,
animale raro e quindi insolito, assurto a simbolo del movimento ambientalista (Figura
17).

Figura 17. L’immagine del panda, simbolo del WWF
Recupero
Per quanto riguarda il recupero delle informazioni dalla
memoria a lungo termine, un aspetto importante è la distinzione fra
riconoscimento e rievocazione. Rievocare
(recall) significa estrarre dalla
memoria un'informazione precedentemente memorizzata: “qual è la capitale del Nicaragua?”, “Quale film hai visto
ieri sera?”, “Come si chiama il Presidente degli Stati Uniti?”. Riconoscere (recognition), invece, significa individuare, fra diverse
alternative, quella (o quelle) che fanno al caso nostro: “La capitale del
Nicaragua è San Josè, Tegucicalpa o Managua?”, “Il Presidente degli Stati Uniti
è Clinton, Bush o Obama?”
Gli esperimenti dimostrano che è più facile riconoscere che
rievocare. Supponiamo di presentare a un soggetto una lista di parole fra loro
scorrelate. Se, in seguito, gli chiediamo
di elencare quelle che si ricorda, egli ne rievocherà un certo numero, che
diminuirà con l’aumentare del tempo intercorso fra presentazione e
rievocazione. Dopo pochi minuti, ne elencherà parecchie, dopo una settimana,
pochissime. Se invece, dopo la presentazione della lista, gliene presentiamo
una seconda, chiedendogli di riconoscere le parole presenti anche nella prima,
la percentuale di parole riconosciute sarà più alta di quelle rievocate. Anche
la capacità di riconoscimento degrada col tempo, ma in modo più lento della
capacità di rievocazione. La Figura 18 mostra i risultati di
un tipico esperimento di confronto fra riconoscimento e rievocazione. In questo
caso, dopo due giorni, i soggetti
riconoscevano ancora il 75% delle parole, ma non erano in grado di
rievocarne praticamente nessuna.
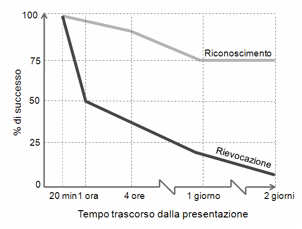
Figura 18. Riconoscimento e rievocazione (Luh, 1922)
È molto importante che il progettista di sistemi interattivi
tenga sempre presente la differenza fra rievocazione e riconoscimento, e il
fatto che le prestazioni dell’utente, nel secondo caso, sono migliori. Quando
si comunicava con i computer esclusivamente con il paradigma “scrivi e leggi” (Capitolo
2), l’utente era costretto a fare continuamente esercizio di rievocazione, per
ricordare i nomi dei comandi del sistema. Con l’introduzione dei terminali
video e poi dei personal computer e l’adozione dei paradigmi “indica e
compila”, all’utente viene solo chiesto di riconoscere il comando desiderato
all’interno di un gruppo di alternative possibili, e non di rievocarne il nome.
Le alternative sono presentate in vari modi: come voci di un menu, come icone in una barra di strumenti, come bottoni in una pulsantiera. Nell’adventure game di Figura 19, i comandi possibili (Examine, Open, Close, Speak, Operate, Go, Hit, Consume) sono elencati sul
video, e l’utente non deve compiere alcuno sforzo di rievocazione.
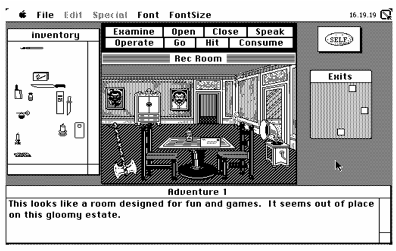
Figura 19. Pulsantiera dei comandi in Uninvited (computer game per Macintosh, della Mindscape, 1986)
In Microsoft Office 2003 (Figura 15), esiste un modo alternativo di selezionare rapidamente le voci, digitando, per ogni
menu, una sola lettera che la identifica univocamente. Per esempio, per
selezionare Open all’interno del menu File, si digitano Alt e F (per aprire il menu File), e quindi O. Oppure, per creare un
nuovo file, si digita Alt seguito da F e da N. L’utente non deve rievocare
le lettere da digitare, ma le deve semplicemente riconoscere. Infatti, sono
evidenziate con una sottolineatura nelle voci dei menu (nel nostro caso, File e Open, vedi figura). Le
difficoltà sorgono, evidentemente, quando le lettere più adatte a rappresentare
una voce sono già utilizzate per altre voci.
I sistemi più evoluti utilizzano spesso, come in questo caso,
sia il riconoscimento che la rievocazione: un comando può essere eseguito
selezionandolo da un menu di alternative (riconoscimento), oppure digitando una
(breve) sequenza di tasti di scelta
rapida, che l’utente deve conoscere (rievocazione). Questa seconda modalità viene
utilizzata dagli utenti più esperti, che desiderano un’interazione più veloce.
Generalizzando, possiamo dire, infatti, che l’interazione basata sul
riconoscimento è più facile ma più lenta, mentre quella basata sulla
rievocazione è più rapida, ma richiede che l’utente sia opportunamente
addestrato.
La visione
Anche per quanto riguarda la visione umana, ci limiteremo a
pochi cenni, relativi agli argomenti di maggiore rilevanza per l’interazione
uomo-macchina.
Quando osserviamo una scena, il nostro sguardo la esplora
seguendo percorsi complessi e irregolari, soffermandosi su quegli elementi cui
prestiamo attenzione. Durante l’esplorazione, l’asse visivo del nostro occhio
si sposta seguendo percorsi che possono essere tracciati dagli apparati di eye-tracking. Questi
dispositivi mostrano che il movimento dei nostri occhi è molto irregolare: lo
sguardo si fissa per un certo tempo su un determinato punto, per acquisire
l’informazione visiva (fissazione), e
quindi si sposta su un altro punto, con un movimento rapidissimo (chiamato saccade) durante il quale l’occhio è
cieco. In media sono eseguite tre-quattro fissazioni al secondo. Approfondiremo
questo tema nel Capitolo 12, quando tratteremo della grafica, e ulteriormente
nel Capitolo 13, a proposito del testo.
L’informazione
visiva viene “proiettata” attraverso il cristallino,
capovolta, sulla retina, una membrana
che riveste la parete interna del globo oculare (Figura 20). Essa è rilevata da cellule sensibili ai
raggi luminosi (fotorecettori), poste
in grande quantità sulla retina, che
la trasformano in segnali elettrici inviati al cervello. Queste cellule sono di
due tipi: i coni (cones), particolarmente sensibili al
colore, che si addensano nell’area centrale della retina (fovea), sull’asse visivo, e i bastoncelli
(rods), molto sensibili alla luce
anche di bassa intensità (visione notturna), ma non al colore, che si addensano
nelle aree periferiche della retina, lontane dall’asse visivo. La sensibilità
dei bastoncelli alle variazioni di luce li rende molto sensibili al movimento.
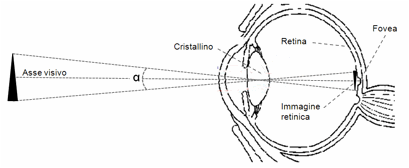
Figura 20. L’occhio umano
La Figura 21 mostra l’andamento della densità dei coni
e dei bastoncelli in funzione dell’angolo visuale dalla fovea. Questa
disposizione dei fotorecettori fa sì che noi distinguiamo meglio i dettagli e i
colori degli oggetti quando li fissiamo direttamente, al centro dell’asse
visivo (visione foveale), e siamo
molto sensibili ai movimenti che percepiamo, come si dice “con la coda
dell’occhio” (visione periferica). La
visione periferica, però, non distingue dettagli né colori, perché è prodotta
solo dai bastoncelli. Il grafico mostra, anche, che il campo di visione a
risoluzione elevata, in cui la densità dei fotorecettori è alta, è abbastanza
ristretto.[15]
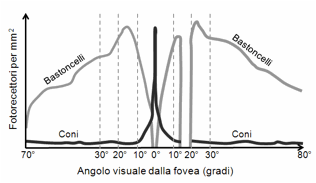
Figura 21. Distribuzione dei fotorecettori sulla retina
Quando fissiamo il puntatore del mouse sullo schermo
di un computer, la nostra visione foveale ci consente di vedere in dettaglio
solo il suo immediato intorno (qualche grado). I nostri occhi lo seguono con continuità, e prestiamo poca – o
nessuna – attenzione a quanto gli è lontano. In questo modo, potremmo non
accorgerci di cambiamenti che occorrono in altre aree del monitor. Quando
questi avvengono, e l’utente li deve considerare, la sua attenzione dovrà
essere “catturata” con mezzi opportuni. Per esempio, con messaggi lampeggianti,
che possano essere percepiti dai bastoncelli alla periferia della retina. Nel
Mac, quando un’applicazione ha qualcosa da segnalare, la sua icona si mette a
“saltellare” nel dock.[16] Il movimento viene percepito
attraverso la visione periferica dell’utente, che
sposta la sua attenzione sull’icona ed esamina il messaggio.
Si dice acuità
visiva (visual acuity) la
capacità dell’occhio di distinguere due punti vicini. Essa si misura considerando l’angolo minimo α sotto
cui devono essere visti perché l’occhio li percepisca separatamente. Se tale
angolo vale 1’[17], le loro immagini si trovano sulla retina
a una distanza di 5 millesimi di millimetro e stimolano due fotorecettori non
contigui, condizione indispensabile perché siano visti come distinti da un
occhio normale. Più precisamente, l’acuità visiva si misura dando il valore
reciproco dell’angolo α, cioè
1/ α. Per esempio, se tale angolo è di 1’,
l’acuità visiva è pari a 1/1, cioè 10/10. Se l’angolo è di 2’, l’acuità visiva
è pari a ½, cioè 5/10.[18]
L’acuità visiva è massima in corrispondenza della fovea centrale, e
diminuisce verso la periferia. Questo è il motivo per cui, per distinguere bene
i particolari di una figura, la dobbiamo fissare direttamente.
L’acuità
visiva è molto variabile da soggetto a soggetto, e tende a diminuire con
l’avanzare dell’età. Secondo la OMS (Organizzazione Mondiale della Sanità), la cecità (blindness) corrisponde a un’acuità visiva inferiore ai 3/60 (anche
con una eventuale correzione, per esempio occhiali). L’acuità compresa fra 3/60
e 6/18, sempre con eventuale correzione, è definita ipovisione (low vision).
Secondo un rapporto della stessa OMS, nel
2006 gli ipovedenti erano ben 269 milioni in tutto il mondo, i ciechi 45
milioni. In totale, 314 milioni di persone: quasi il 5% della popolazione del
pianeta.[19]
La maggior parte sono anziani; le donne sono più a rischio degli uomini,
a tutte le età. In sostanza, la percentuale delle persone che hanno gravi
problemi di visione (visually impaired)
è molto significativa.
Le
differenze fra le persone non riguardano solo l’acuità visiva, ma anche la
capacità di distinguere correttamente i colori. Nell’occhio umano, come abbiamo
già detto, la percezione dei colori è affidata ai coni della retina. Queste
cellule sono di tre tipi, ciascuno sensibile alla luce di un certo intervallo
di lunghezze d’onda. I tre tipi di
coni sono chiamati R (Red), G (Green) e B (Blue), secondo la sensazione cromatica che si sperimenta quando un
particolare tipo è più attivo degli altri. La Figura 22 mostra il grafico della sensibilità dei
tre tipi di coni, in funzione delle lunghezze d’onda dello spettro visibile. Si
vede, per esempio, che i coni R sono quelli più sensibili alla luce di lunghezza
d’onda elevata, con una sensibilità massima attorno ai 570 nm (nanometri),
corrispondente al giallo.[20]
In tal
modo, quando un fascio di luce colorata colpisce la retina, le sue componenti
cromatiche vengono percepite dai coni ad esse più sensibili, che invieranno in
risposta segnali elettrici di intensità diversa al cervello. La Figura 22 mostra come un fascio di luce azzurra (di
lunghezza d’onda attorno ai 500 nm) e uno arancione (di 600 nm) producono
risposte di intensità diversa da ciascun tipo di coni. Per esempio, la luce
azzurra produce nei coni G una risposta superiore a quella dei coni R, e molto
superiore a quella dei coni B. Quella arancione, invece, eccita i coni R più
dei coni G, e i coni B quasi per nulla. Questi segnali elettrici di intensità
diversa, elaborati dal cervello, ci fanno vedere due colori differenti.
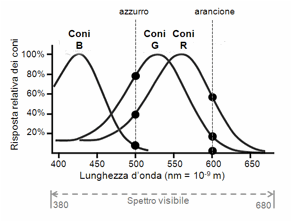
Figura 22. Sensibilità dei coni R, G, B dell’occhio umano
Quando
i coni di un certo tipo sono difettosi, o mancanti, la visione del colore viene
alterata, perché la componente cromatica ad essi associata non viene percepita.
Se, per esempio, non funzionano i coni di tipo R, l’occhio non vede la
componente rossa, e i colori che la contengono risulteranno alterati.
Quest’alterazione nella percezione dei colori si chiama cecità cromatica (color
blindness), o anche daltonismo.[21] I tipi di daltonismo sono diversi, a
seconda dei tipi di coni difettosi. Quello più frequente è causato dal
difettoso funzionamento dei coni G, e determina una riduzione della sensibilità
al verde. La conseguenza è una difficoltà a distinguere le differenze
cromatiche nella regione rosso-arancio-giallo-verde dello spettro. Tale
anomalia è presente in un gran numero di persone: secondo alcune stime, negli
Stati Uniti circa il 7% degli uomini e lo 0,4% delle donne.[22]
La
diffusione della cecità cromatica richiede grande attenzione nella
progettazione delle interfacce visive dei sistemi interattivi. È necessario
evitare che le informazioni rilevanti siano veicolate esclusivamente attraverso
il colore. Infatti, gli utenti che non possono distinguere i colori utilizzati
per comunicare queste informazioni non sarebbero in grado di comprenderle. In
particolare, non bisogna mai assumere che gli utenti sappiano distinguere il
rosso dal verde, perché questa è la forma di cecità cromatica più diffusa
(invece, la grande maggioranza delle persone riesce a distinguere correttamente
il giallo e il blu). Alcuni esempi a questo proposito sono discussi nel Capitol
12 (Figure 29 e 33).
Quando
poi consideriamo anche gli utenti ipovedenti o ciechi, i problemi si fanno
molto più complessi, data anche la varietà di patologie esistenti, e le
tecniche utilizzabili. In questo libro di carattere introduttivo non è
possibile entrare nei dettagli, per i quali rimandiamo ai testi specializzati.
I
meccanismi della visione umana hanno notevoli implicazioni sulla progettazione
dei sistemi interattivi. Alla progettazione grafica sarà interamente dedicato
il Capitolo 12 e, per quanto riguarda gli aspetti relativi alla leggibilità dei
testi, parte del Capitolo 13.
Il sistema motorio
Per quanto riguarda il processore motorio, ricorderemo qui
soltanto due temi importanti: l’apprendimento motorio, e la legge di Fitts.
Apprendimento motorio
Con questo termine s’intende l’apprendimento di particolari
sequenze di movimento che coinvolgono l’apparato muscolare, come giocare a
golf, suonare il piano, pronunciare parole in una lingua straniera. L’utilizzo
dei sistemi interattivi, spesso, presuppone qualche forma di apprendimento
motorio, che richiede un particolare coordinamento fra occhio e mano (eye-hand coordination). Per esempio, per
l’uso di device di manipolazione diretta, quali mouse, touchpad, trackball,
tavoletta grafica, joystick. In qualche caso l’apprendimento può richiedere molto
tempo, come nei programmi di grafica, che richiedono molta manualità e un
perfetto coordinamento occhio-mano, e i computer game d’azione, in cui
l’eccellenza nel gioco si raggiunge solo dopo un lungo esercizio. Ovviamente, non tutti i sistemi sono
impegnativi come un computer game.
Anche operazioni apparentemente molto semplici, per esempio il
doppio-click del mouse, richiedono apprendimento. Tuttavia, anche i sistemi più
semplici richiedono qualche tipo di abilità, che l’utente non è sempre in grado
di sviluppare agevolmente. Per esempio, come abbiamo già osservato, gli anziani
possono avere difficoltà a svolgere compiti manuali anche elementari, come
l’interazione con un telefono cellulare o con un mouse. I sistemi interattivi
destinati a un’utenza generale dovrebbero pertanto possedere un’elevata apprendibilità (Capitolo 3) anche per
quanto riguarda questi aspetti. Quando il sistema richiede comunque
l’apprendimento di abilità motorie particolari, dovrebbe essere sempre permesso
di adattarne i parametri alle esigenze individuali degli utilizzatori. Per
esempio, nel caso del mouse, modificando la velocità del doppio clic, o
addirittura eliminando certe funzioni, come lo zoom effettuato con la rotellina
superiore (Figura 23).
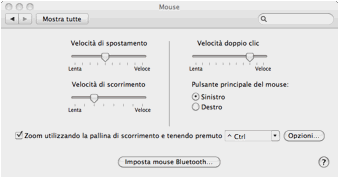
Figura 23. Personalizzazione del mouse (MacOS Finder 10.6, 2009)
Come ogni tipo di apprendimento, anche quello motorio
procede per gradi. Inizialmente, eseguiamo i movimenti in modo approssimato,
incerto, commettendo frequenti errori; queste prime prove ci forniscono
tuttavia dei feedback che ci permettono di correggerci. Con la ripetizione, il
movimento si fa più fluido e preciso, e facciamo meno errori. Via via che
procediamo nell’addestramento, le nostre prestazioni migliorano. Un elemento
essenziale in questo processo è la presenza di feedback. Esso ci permette di
confrontare le intenzioni con i risultati, e di correggere il movimento di
conseguenza. Senza feedback le nostre prestazioni non migliorano, perché
operiamo, per così dire, alla cieca: secondo il modello di Norman, il golfo
della valutazione è troppo ampio, e non c’è apprendimento.
Il feedback può essere qualitativo,
come per esempio quando impariamo il movimento che ci permette di ingrandire o
rimpicciolire una fotografia dello schermo multi-touch dell’iPhone (Figura 12,
Capitolo 2). In questo caso, in corrispondenza del movimento delle nostre dita,
l’immagine si modifica in modo continuo. Quando riteniamo che l’immagine abbia
raggiunto – più o meno –
la dimensione desiderata, ci fermiamo.
Oppure, il feedback può essere quantitativo,
come quando impostiamo l’ora della sveglia, ancora sull’iPhone (Figura 14,
Capitolo 3). In questo secondo esempio, selezioniamo l’ora della sveglia
strisciando il dito sulla rotella delle ore, che ruota in modo corrispondente
al movimento. A differenza di prima, però, la rotella ci mostra in ogni istante
ora e minuti selezionati. Siamo così in grado di valutare con precisione quanto manca al raggiungimento
dell’obiettivo, e di graduare il nostro movimento, in maniera più fine. Quando
il feedback è quantitativo, come in questo caso, l’apprendimento è solitamente
più preciso, e facciamo meno errori.
Nei casi specifici, possiamo quantificare i miglioramenti
prodotti dall’apprendimento, per esempio contando gli errori commessi in
funzione del numero di prove. Quante prove servono per imparare a mandare una
pallina in buca con una mazza da golf? Quanti tasti occorre premere per
imparare a scrivere al computer raggiungendo certe prestazioni? Queste
valutazioni si possono effettuare con degli opportuni esperimenti. In generale,
si trova che il tempo necessario per effettuare un compito motorio diminuisce
con la pratica, secondo una legge di potenza: la cosiddetta legge di potenza della pratica (Power Law of Practice).
Questa legge ci dice che, se T1 è il tempo impiegato per eseguire la prima prova, Tn è il tempo impiegato per effettuare l’n-esima prova
Tn = T1 n -a
dove a è una costante che dipende dal
tipo di compito, il cui valore si trova tipicamente nell’intervallo 0.2 - 0.6.
La curva rappresentata da questa equazione è quella di Figura 24. In pratica, essa ci
dice che il tempo necessario per effettuare un compito (per esempio, annodarsi
la cravatta), all’inizio migliora sensibilmente ad ogni nuova prova. Via via
che il numero delle prove aumenta, i miglioramenti si fanno sempre più modesti.
Quando sappiamo fare il nodo velocemente, ulteriori miglioramenti richiedono
moltissimo esercizio. Questa legge esprime in modo preciso un fatto ben noto,
che tutti abbiamo sperimentato. È relativamente facile imparare a tirare una
pallina con una mazza da golf, e i progressi durante le prime ore di lezione
con un istruttore possono essere molto incoraggianti, ma poi i miglioramenti
diventano più lenti. E per diventare campione del mondo è necessario
esercitarsi molto, molto a lungo.
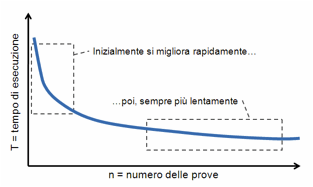
Figura 24. Legge di potenza della pratica
La curva di Figura 24, valutata per un
particolare compito motorio su un campione significativo di utenti, visualizza,
in pratica, la curva di apprendiment
media (learning curve) di quel compito. Se la curva
scende molto in fretta, avvicinandosi alle ascisse quasi subito, significa che
il compito è molto facile da apprendere. Se la curva scende lentamente,
significa che, per il campione di utenti con i quali è stato condotto
l’esperimento, il compito è difficile.
L’interazione con i sistemi interattivi spesso si sviluppa
soprattutto sul piano cognitivo, senza richiedere all’utente abilità manuali particolarmente
complesse. Ci si limita di solito alla digitazione di caratteri con una
tastiera (reale o virtuale) di varie dimensioni, e al puntamento su uno
schermo, direttamente col dito (touch screen) o mediante device di
manipolazione indiretta (mouse, touchpad, o simili). La facilità di
apprendimento dell’uso di questi device, proprio per la loro grande diffusione,
è un elemento fondamentale della usabilità complessiva del sistema.
La legge di Fitts
Una delle azioni più frequenti che
compie chi interagisce con un sistema è quella di spostare il dito (o un
sostituto del dito, come il puntatore del mouse) su un bersaglio. Per esempio,
quando muoviamo un dito per premere un tasto della tastiera o un bottone su un
touch screen, oppure quando muoviamo il puntatore del mouse sulla voce di un
menu per selezionarla, e così via. In tutti questi casi, possiamo utilizzare un
modello matematico per prevedere il tempo T necessario per raggiungere il
bersaglio, in funzione della sua dimensione S e della distanza D dal punto di partenza.
Questo modello è stato proposto
dallo psicologo americano Paul Fitts nel 1954, ed è quindi noto come legge di Fitts.[23] ci fornisce. Essa stabilisce
che:
T = a + b log2 (D/S
+ 1)
Dove:
T è il tempo medio
necessario per effettuare il movimento;
D è
la distanza fra il punto di partenza e il centro del bersaglio (Figura 25);
S è la dimensione (size) del bersaglio, misurata lungo
l’asse del movimento. S può anche essere considerato il
margine di tolleranza sulla posizione finale, poiché questa deve cadere
nell’intervallo ±S/2 dal centro del bersaglio (Figura
25);
a e b sono due costanti che dipendono
dallo strumento di puntamento utilizzato: dito, mouse, touchpad, trackball, e
così via, e devono essere ricavate sperimentalmente.
In particolare, a rappresenta il
tempo necessario per mettere in movimento/fermare il device (per la mano libera
è nullo).
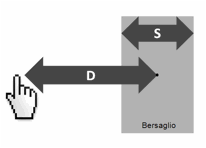
Figura 25. I parametri della legge di Fitts
In sostanza, la
legge di Fitts dice che tempo T necessario per muovere la mano su un
bersaglio di dimensione S a
distanza D dipende
dalla precisione relativa richiesta (rapporto D/S). Così,
per esempio, il tempo per raggiungere un bersaglio di 2 cm da una distanza di
20 cm è uguale al tempo necessario per raggiungere un bersaglio di 1 cm da una
distanza di 10 cm, perché 2/20 = 1/10. Se la distanza è grande e il bersaglio
piccolo, ci vorrà un tempo maggiore di quello necessario per raggiungere un
bersaglio grande da una distanza breve.
Consideriamo la Figura
26a, e supponiamo che il
tempo necessario per spostare il dito sul bottone dalla distanza indicata dalla
freccia sia T0. Se
desideriamo ridurre questo tempo di un certo ΔT, per
esempio del 30%, potremo muovere il bottone più vicino al punto di partenza
(soluzione b in figura), oppure, lasciando invariata la distanza, ingrandire
opportunamente il bottone (soluzione c).[24]
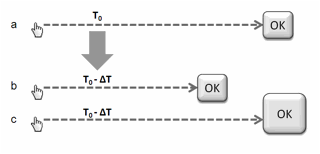
Figura 26. Conseguenze della legge di Fitts
La legge di Fitts si può applicare a una varietà di
situazioni, per modellare azioni di point&clic, o di drag&drop con
svariati pointing device. Ciò che
cambia sono le costanti della formula, che devono essere derivate
sperimentalmente. In ogni caso, si applica solo ai movimenti lungo una sola
dimensione, in condizioni di abilità normali (cioè, senza particolari,
specifici allenamenti). Non si può, evidentemente, applicare alla presenza di
ausilii software che servano a facilitare il movimento, per esempio bersagli
che attirino a sé il puntatore.
La legge di Fitts non sorprende: anche se non conosciamo la
relazione matematica precisa che lega D e S, è abbastanza ovvio
che, ingrandendo il bersaglio o diminuendo la distanza dal punto di partenza,
questo viene raggiunto più in fretta. Ci si aspetterebbe quindi che i sistemi
fossero progettanti in modo da tenere in debito conto questo fatto elementare.
È sorprendente, invece, quanto spesso ciò non avvenga. Un caso molto frequente
è costituito dai bottoni di una pagina web. La Figura 27 mostra una porzione del
menu principale di www.repubblica.it. Mentre per ogni voce di primo livello l’intera area grigia
è cliccabile, per quelle di secondo livello bisogna cliccare esattamente sul
testo: l’area circostante non è sensibile al clic del mouse. Ciò restringe
inutilmente la dimensione del bottone, già molto ridotta per la lunghezza del
menu. Rendere cliccabile l’intera
area bianca attorno ad ogni voce aumenterebbe l’usabilità, senza utilizzare
spazio aggiuntivo.
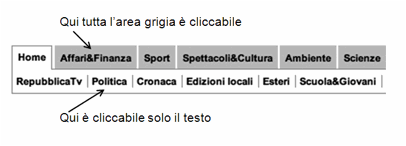
Figura 27. Il menu principale della homepage di www.repubblica.it (2010)
Questa soluzione è stata, invece, adottata nelle pulsantiere
delle applicazioni di Office 2007, proprio considerando la legge di Fitts. Qui,
i progettisti hanno reso sensibile al clic tutta l’area attorno ad ogni icona,
includendo anche l’etichetta (Figura 28).
Un altro accorgimento suggerito dalla legge di Fitts è di
utilizzare, al posto degli abituali menu a tendina, dei menu pop-up, che
appaiono accanto al puntatore quando si preme il tasto destro del mouse. Questi
hanno il vantaggio di ridurre la distanza fra il punto di partenza e il
bersaglio. La Figura 29 mostra una variante
insolita dei menu pop-up: una pulsantiera pop-up, realizzata in Word 2007. Quando, durante la scrittura del testo,
si seleziona una parola e si sposta il mouse di qualche pixel verso l’alto,
accanto ad essa appare un pop-up con i bottoni più usati per cambiare gli
attributi del testo. Le diverse opzioni sono molto vicine alla parola, e il
percorso del puntatore verso il bersaglio si accorcia notevolmente. La
pulsantiera svanisce automaticamente se si riporta il cursore un po’ più in
basso, o se si prosegue nella scrittura, in modo da non intralciare l’utente.
Figura 29. Pulsantiera pop-up in Microsoft Word 2007
Una variante dei menu pop-up è
costituita dai menu a torta (pie menu), come quello di Figura
30, usato in Second Life. Cliccando sul tasto destro del
mouse, questi menu compaiono proprio attorno al puntatore, che rimane visibile
al centro. Le voci sono disposte a raggiera, equidistanti dal puntatore: in
questo modo, il tempo necessario per raggiungerle è lo stesso per tutte. Le
prestazioni sono ulteriormente migliorate dalla forma “a cuneo” delle voci del
menu, che aumenta sensibilmente la superficie di ogni bersaglio, rispetto ai
tradizionali menu a tendina.

Figura 30. Pie menu in Second Life
Una conseguenza interessante della
legge di Fitts è che i bersagli disposti lungo i bordi dello schermo sono
particolarmente veloci da raggiungere. Infatti, il puntatore non può
oltrepassare il bordo, comunque lo si muova: nella formula di Fitts è come se
il bersaglio avesse dimensione S infinita, e quindi sarebbe,
semplicemente, T=a. Per questo motivo, la barra dei
menu delle applicazioni nel Mac, che si trova al bordo superiore del monitor,
si raggiunge in modo più rapido di quella delle applicazioni di Windows, che si
trova sul bordo superiore della finestra che contiene l’applicazione. Infatti, il bordo della finestra può
essere oltrepassato dal puntatore, a differenza del bordo del monitor, e quindi
il movimento per raggiungere il bersaglio risulta inevitabilmente più lento.
Una soluzione ancora migliore, per
quanto riguarda la legge di Fitts, è quella in cui il bersaglio si trova in uno
dei quattro angoli del monitor. In questo caso, infatti, i bordi dello schermo
fungono da guida per il cursore, il quale, anche se diretto in modo
approssimativo, “scivola” lungo il bordo fino a raggiungere l’angolo. Da questo
punto di vista, il bottone START di Windows, che tradizionalmente si
trova nell’angolo inferiore sinistro dello schermo, è in una posizione ideale.
Questa favorevole posizione non era, però, correttamente sfruttata in Windows
95, perché il bottone era separato
dal bordo della schermo da un margine di pochi pixel, non sensibili al clic del
mouse, come si vede in Figura
31 (in alto). A causa di questi pochi pixel, quando il
cursore toccava il bordo dello schermo, si trovava fuori bersaglio, e il
pulsante non poteva essere selezionato. Questo errore, in seguito, è stato
corretto. La Figura
31 (in basso) mostra il pulsante START in Windows XP, che si estende infatti fino ai bordi del monitor. Per lo
stesso motivo, il grosso pulsante circolare comune a tutta la suite Office 2007
è stato posto nell’angolo in alto a sinistra dello schermo.[25]

Figura 31. Il bottone START in Windows 95 (in alto) e in Windows XP (in basso)
L’utente nel suo contesto
Nelle pagine precedenti abbiamo visto diversi esempi che
mostrano come lo studio dell’usabilità dei sistemi interattivi non possa
prescindere dallo studio della percezione e della cognizione umana e delle
abilità che derivano dalla struttura psico-fisica delle persone. Anche se
queste analisi cercano spesso di individuare le caratteristiche e le
prestazioni funzionali cosiddette normali,
cioè che caratterizzano l’essere umano “medio”, le differenze individuali
emergono continuamente, e possono essere sostanziali.
Queste differenze si rivelano ancora più marcate quando
ampliamo i nostri studi e, dalla sfera della psicologia, ci portiamo in quella,
più generale, dell’antropologia, per studiare l’uomo nella sua globalità: dal punto di vista sociale, culturale e dei suoi
comportamenti quotidiani. Anche questi studi sono importanti per chi si occupa
di usabilità, perché gli artefatti dell’uomo e i suoi comportamenti,
individuali e sociali, sono strettamente legati.
Infatti,
l’influenza reciproca fra strumenti e comportamenti è molto profonda,
soprattutto per gli strumenti a più ampia diffusione. Abbiamo già osservato
come la diffusione “epidemica” di nuovi strumenti di comunicazione interattiva
(il telefono cellulare, gli sms, la posta elettronica, i social network) abbia
radicalmente trasformato nell’arco di pochi anni i comportamenti comunicativi
della popolazione, almeno (per ora) dei paesi a più alto reddito. Al momento
della stesura di questo libro, secondo Facebook, ciascuno dei 400 milioni di
utenti del sito vi trascorre, in media, più di 55 minuti al giorno.[26] Questo a meno di sei anni dalla nascita del
servizio. D’altro canto, la diffusione delle nuove modalità di
comunicazione influenzano a loro
volta l’evoluzione degli strumenti, che vengono continuamente modificati e
migliorati via via che gli utilizzatori ne scoprono nuovi impieghi.
La
rapidità e la dimensione di queste trasformazioni fa sì che le loro
implicazioni siano ancora poco note. Per analizzarle, ci possiamo avvalere dei
metodi e degli strumenti delle scienze dell’uomo. Queste indagini sono molto
importanti, non solo perché ci permettono di “conoscere”, ma anche, e
soprattutto, perché ci possono orientare al “fare”. Gli studi dell’interazione uomo-macchina, intesa nel senso
più ampio d’interazione società-tecnologia,
possono aiutarci a capire meglio quali scelte progettuali siano utili per il
miglioramento complessivo della qualità della vita delle persone, e quali
producano effetti indesiderabili.
I sistemi
non esistono solo nelle vetrine di chi li vende, isolati da tutto, ma vivono
nel mondo, nell’interazione continua con esso, ed è anche da questo punto di
vista che devono essere considerati. Studiando i comportamenti che si
sviluppano “attorno” ai sistemi, e nell’interazione con le persone, siamo in grado
di capire che cosa deve essere migliorato, che cosa non va e, soprattutto, che
cosa potrebbe essere fatto e ancora non c’è. Questi comportamenti non
riguardano solo il singolo utilizzatore, nel suo rapporto con il sistema, ma
l’intera comunità delle persone che cooperano in uno stesso contesto ambientale
e sociale, siano o meno coinvolti anch’essi con il sistema.
Consideriamo l’esempio della Figura 32. Essa mostra un reparto
ospedaliero di pediatria, in cui ai bambini ricoverati, a volte con degenze
molto lunghe e lontani dalla propria città, è stato dato in dotazione un
personal computer connesso a Internet. Ciò ha permesso di ridurre la “distanza”
fra la permanenza in ospedale e la vita di tutti i giorni, permettendo ai
piccoli pazienti non solo di giocare e di navigare su Internet, ma anche di
rimanere in contatto con la famiglia e gli amici attraverso Skype, chat e posta
elettronica, e con le attività didattiche della propria scuola. Alcuni bambini,
di origine straniera, hanno potuto restare in contatto diretto con la famiglia
lontana, residente nel paese di provenienza. Si tratta di un progetto
tecnologicamente piuttosto semplice, che si avvale di tecnologie standard e si
può realizzare rapidamente e a basso costo, ma di elevato valore sociale.[27] È evidente che l’analisi di questo sistema non può limitarsi allo studio
della semplice interazione del singolo bambino con il computer a esso affidato.
Il bambino e il suo computer sono parte di un sistema organizzativo, sociale e
umano più ampio, composto di numerosi attori: medici, infermieri, genitori,
amici, altri bambini ricoverati. Alcuni attori sono lontani, e intervengono
attraverso la rete con modalità diverse (video, audio, messaggi testuali, in
diretta o in differita). Altri sono vicini, in visita nel reparto, e potrebbero
anch’essi utilizzare il computer per scopi ancora diversi. Per esempio, i
genitori che assistono i bambini in ospedale potrebbero tenersi in contatto con
il posto di lavoro, da cui si sono temporaneamente allontanati. E poi ci sono
le possibili interazioni con la scuola e i suoi insegnanti, che apre
interessanti prospettive di prosegimento dell’attività scolastica a distanza.
La presenza dei computer determina la nascita di un contesto del tutto nuovo,
nel quale si formano nuovi comportamenti e si delineano nuove esigenze.
Per comprendere questo nuovo
contesto, individuarne gli eventuali problemi e le possibili soluzioni, è
necessario studiarlo da vicino, ed eventualmente “immergervisi” e sperimentarlo
di persona. Questo è l’obiettivo che si propongono i cosiddetti studi sul campo (field study). I metodi
per questi tipi di analisi sono quelli dell’etnografia.

Figura 32. Utilizzo di Internet in un reparto di pediatria (cortesia Informatici Senza Frontiere)
L’etnografia
L’etnografia è un metodo ben consolidato nel campo delle ricerche
sociali e antropologiche, sviluppato dalla fine dell’800, quando le potenze
coloniali sentivano la necessità di approfondire la conoscenza delle loro
colonie. Il ricercatore etnografico, da solo o in team, s’immerge nelle
attività quotidiane di una società, comunità o organizzazione, allo scopo di
raccogliere dei dati che, una volta interpretati, permettano di comprenderne la
cultura, l’organizzazione, i comportamenti, le usanze. L’etnografo, come
suggerisce il nome,[28] non costruisce teorie o modelli della società, si limita a raccogliere e a
registrare informazioni, che saranno utilizzate da altri.[29] Immergendosi direttamente nell’ambiente oggetto di studio, è in grado di
raccogliere dati che sarebbe impossibile ottenere in altri modi. Lavora con
l’osservazione diretta, con interviste o questionari; a volte diventando
anch’egli, per il periodo dello studio, parte attiva della comunità che
descrive. L’etnografo esamina il contesto complessivo, nella convinzione che le
comunità si comprendano meglio considerandone tutti gli aspetti: i
comportamenti, l’ambiente, gli artefatti, i riti, la lingua, la cultura, i
valori, le credenze, e così via. Registra, ma non esprime giudizi, nella convinzione
che ogni cultura debba essere compresa basandosi sui propri parametri, e non su
quelli dell’osservatore.
Dagli anni ’90, i metodi
dell’etnografia sono stati adottati anche nella human-computer interaction, e
in particolare nell’ambito della progettazione dei sistemi interattivi. In
quest’area, gli obiettivi delle ricerche dell’etnografo possono essere diversi.
In alcuni casi avrà il compito di osservare l’utilizzo dei prodotti della
tecnologia in un certo contesto, per esempio il reparto pediatrico della Figura 32, per individuarne i problemi e riportarli ai progettisti per i necessari
interventi migliorativi. In altri casi avrà il compito di analizzare i
comportamenti all’interno di un gruppo o di un’organizzazione, per fare
emergere i bisogni ancora inespressi, che possono suggerire prodotti o servizi
nuovi. Per esempio, osservando i comportamenti all’interno di un reparto
ospedaliero non ancora informatizzato, per individuarne necessità e problemi.
In ogni caso, il suo scopo è di osservare, comprendere e descrivere i
comportamenti dell’utente (attuale o potenziale), per riportarli a chi
progetterà le soluzioni più adatte. Per questo, la formazione del ricercatore
etnografico è di solito specifica: egli proviene dalle scienze umane, e non
dall’informatica o dalla progettazione dei sistemi.
Andy Crabtree, autore di un libro
sui metodi dell’etnografia nella progettazione dei sistemi collaborativi,[30] in un suo articolo così descrive il lavoro dell’etnografo in questo campo:
L’etnografia opera come i nostri
“occhi e orecchi sul campo”, per informarci sulle pratiche correnti, il cui
significato altrimenti passerebbe inosservato. Il ruolo dell’etnografia nella
progettazione, così come è emerso nei nostri studi, consiste nella sua capacità
di fornire il senso concreto degli aspetti reali di un certo ambiente: vedere
le attività come azioni sociali immerse in un dominio socialmente organizzato,
compiute attraverso le attività quotidiane dei suoi abitanti, e comunicare
queste informazioni ai progettisti. Questo approccio si focalizza sulle
specifiche attività che i progettisti desiderano comprendere, analizzare e
ricostruire, e le documenta. È la capacità dell’etnografia di descrivere
l’ambiente sociale così come viene percepito dagli “utenti”, che la fa
apprezzare dai progettisti. Di conseguenza, l’etnografia è molto valida
nell’identificare le eccezioni, le contraddizioni e le contingenze delle
attività lavorative, che costituiscono le reali condizioni dell’ambiente ma che
di solito non figurano nelle descrizioni ufficiali o formali.[31]
Per esempio, durante uno studio sul
campo presso un’organizzazione aziendale, il ricercatore etnografico potrà
raccogliere le seguenti informazioni:
· Organigrammi aziendali e ordini di servizio che definiscono le responsabilità e ruoli assegnati all’interno dell’organizzazione;
· Procedure di lavoro formalizzate per l’esecuzione delle attività, e relativa modulistica;
· Raccolta di artefatti rilevanti utilizzati, quali esempi di moduli compilati, diagrammi, tabulati, comunicazioni interne;
· Differenze osservate fra i ruoli ufficiali e quelli informali;
· Descrizione di come le procedure ufficiali vengono effettivamente eseguite, e delle cause delle eventuali deviazioni;
· Schemi dei processi di lavoro osservati, e descrizione delle difficoltà;
· Descrizione di come sono gestite le situazioni anomale o eccezionali;
· Layout e fotografie degli ambienti di lavoro, con l’indicazione degli spostamenti abituali;
· Registrazione di interviste significative con le persone dell’organizzazione;
· Video o foto di situazioni rilevanti.
Queste ricerche possono essere
svolte in ambienti molto diversi, e non necessariamente all’interno di
organizzazioni formali come un’azienda, un ospedale, un ente pubblico. Possono
svolgersi presso comunità informali, come un quartiere, un villaggio, un gruppo
sociale, allo scopo di analizzare come determinati prodotti o servizi vengano
utilizzati nella vita quotidiana, o individuare necessità ancora inespresse.
Il ricercatore etnografico si trova al confine fra due mondi: quello delle scienze dell’uomo, e quello
della progettazione (Figura 33). Raccoglie informazioni che
dovranno permettere di incrociare i bisogni degli utenti con le possibilità
della tecnologia. Può essere un
compito difficile, soprattutto quando i bisogni sono inespressi, e i potenziali
destinatari di una soluzione non sono in grado di descrivere con chiarezza le
loro esigenze. Sentono il disagio della situazione corrente, ma non sanno
metterne a fuoco le cause e indicarne le possibili soluzioni. Gli utenti
raramente conoscono le potenzialità della tecnologia corrente, e tendono a
ritenere che ciò che non è mai stato fatto non si possa fare. Non sanno che
cosa chiedere, e, di conseguenza, i progettisti non sanno che cosa dare. Il
ricercatore etnografico ha il compito di facilitare questo incrocio.
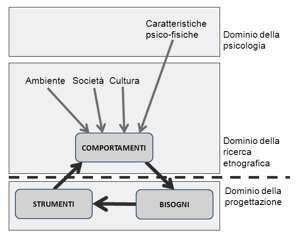
Figura 33. I diversi domini nello studio dell’utente
Per questa sua posizione
“borderline”, può interpretare il suo ruolo in modi diversi. Alcuni lo
considerano un ruolo ancillare, di puro supporto al progettista: i suoi “occhi
e orecchi” sul campo, come afferma il brano sopra citato. Altri, andando oltre
i metodi dell’etnografia tradizionale, interpretano il proprio ruolo in modo
più ampio: non si limitano a descrivere ciò che vedono, ma cercano di estrarne
il senso, dandone una lettura
critica, che possa orientare il progetto in modo sostanziale:[32]
Comprendere la
esperienza dell’utente con le tecnologie richiede attenzione ai significati
sociali e culturali: che cosa significa il prodotto per l’utente, che cosa
significa nel contesto di particolari culture, e che cosa significa nei termini
del suo impatto complessivo sull’ambiente sociale e globale? Attraverso il
possesso e l’uso di particolari tecnologie e artefatti, noi facciamo
dichiarazioni su noi stessi e sui nostri valori. Nella progettazione,
produzione e commercializzazione di nuove tecnologie digitali, noi, anche,
introduciamo e normalizziamo certi tipi d’interazione sociale e di valori. […]
La human-computer interaction si avvale già di discipline non ingegneristiche
come l’etnografia e il design, allo scopo di comprendere meglio l’esperienza e
l’estetica nel design della tecnologia. Discipline basate sulle scienze umane,
come l’antropologia, la letteratura, e gli studi sulle culture e sui media,
possono fornire un ulteriore insieme di tecniche e metodi per comprendere come
ci rapportiamo alla tecnologia e agli artefatti culturali.[33]
Ripasso ed esercizi
1. Che cosa s’intende per human information processor?
2. Quali indicazioni fornisce lo studio dell’attenzione al progettista di sistemi interattivi?
3. Spiega le relazioni fra i sistemi di memoria umana, secondo il modello modale.
4. Quali sono le caratteristiche della memoria e a breve termine?
5. A che cosa si riferisce il “magico numero sette” e quali implicazioni ha sull’usabilità dei sistemi interattivi?
6. Cerca, nei programmi che utilizzi normalmente, una funzione che sovraccarica in modo eccessivo la memoria a breve termine dell’utente.
7. Come possiamo facilitare la codifica delle informazioni nella memoria a lungo termine?
8. Spiega la differenza fra riconoscimento e recupero in relazione alla memoria a lungo termine.
9. Quali implicazioni hanno le caratteristiche della memoria a lungo termine sull’usabilità dei sistemi interattivi?
10. Come si definisce l’acuità visiva?
11. Che cosa s’intende per visione foveale e visione periferica?
12. Che cosa s’intende per cecità cromatica, e a che cosa è dovuta?
13. Fra i programmi che usi di frequente, quali richiedono apprendimento motorio? Quali tipi di feedback forniscono?
14. Spiega la legge di potenza della pratica.
15. Spiega la legge di Fitts, e le sue implicazioni sull’usabilità dei sistemi interattivi.
16. Considerando la legge di Fitts, quali tipi di menu permettono prestazioni migliori?
17. Che cos’è l’etnografia?
18. Quale ruolo ha il ricercatore etnografico nella human computer interaction?
Approfondimenti e ricerche
1. Per approfondire i meccanismi dell’attenzione, della memoria e, più in generale, della cognizione umana si può partire da un manuale universitario di psicologia generale. Per esempio, P.Gray, Psicologia (Seconda edizione italiana condotta sulla quarta edizione americana), Zanichelli, 2004.
2. In rete esistono numerosi servizi gratuiti che simulano i diversi tipi di cecità cromatica, mostrando come certi gruppi di colori sarebbero visti da chi ne è affetto. Per esempio, http://colorschemedesigner.com o http://www.vischeck.com. Esperimenta qualcuno di questi servizi, identificando le scelte cromatiche più adatte anche per chi ha problemi nella distinzione dei colori.
3. Approfondisci le possibili applicazioni della legge di Fitts nella progettazione di sistemi interattivi. Suggerimento: Bruce Tognazzini, nel suo sito web, propone una interessante serie di quiz (con relativa risposta) sull’applicazione di questa legge a tipici problemi di design (http://www.asktog.com/columns/022DesignedToGiveFitts.html).
4. Analizza l’interfaccia utente di alcuni siti web di grande diffusione dal punto di vista della legge di Fitts. A tuo parere, i progettisti ne hanno tenuto conto nel design dal layout grafico?
5. Approfondisci il ruolo e i metodi dell’etnografia per la progettazione di sistemi interattivi. Un buon punto di partenza può essere l’articolo di M.D.Myers, Investigating Information Systems with Ethnographic Research, in Communications of the Association for Information Systems, vol.2, article 23 (1999), disponibile anche in rete in http://www.qual.auckland.ac.nz/Myers%20CAIS%20article.pdf.